Vectorless RAG: Building AI Search Without a Vector Database
RAG does not always require embeddings or a vector database. Learn how vectorless RAG retrieves useful context with keyword search, SQL, metadata, document structure, and LLM-guided reasoning.
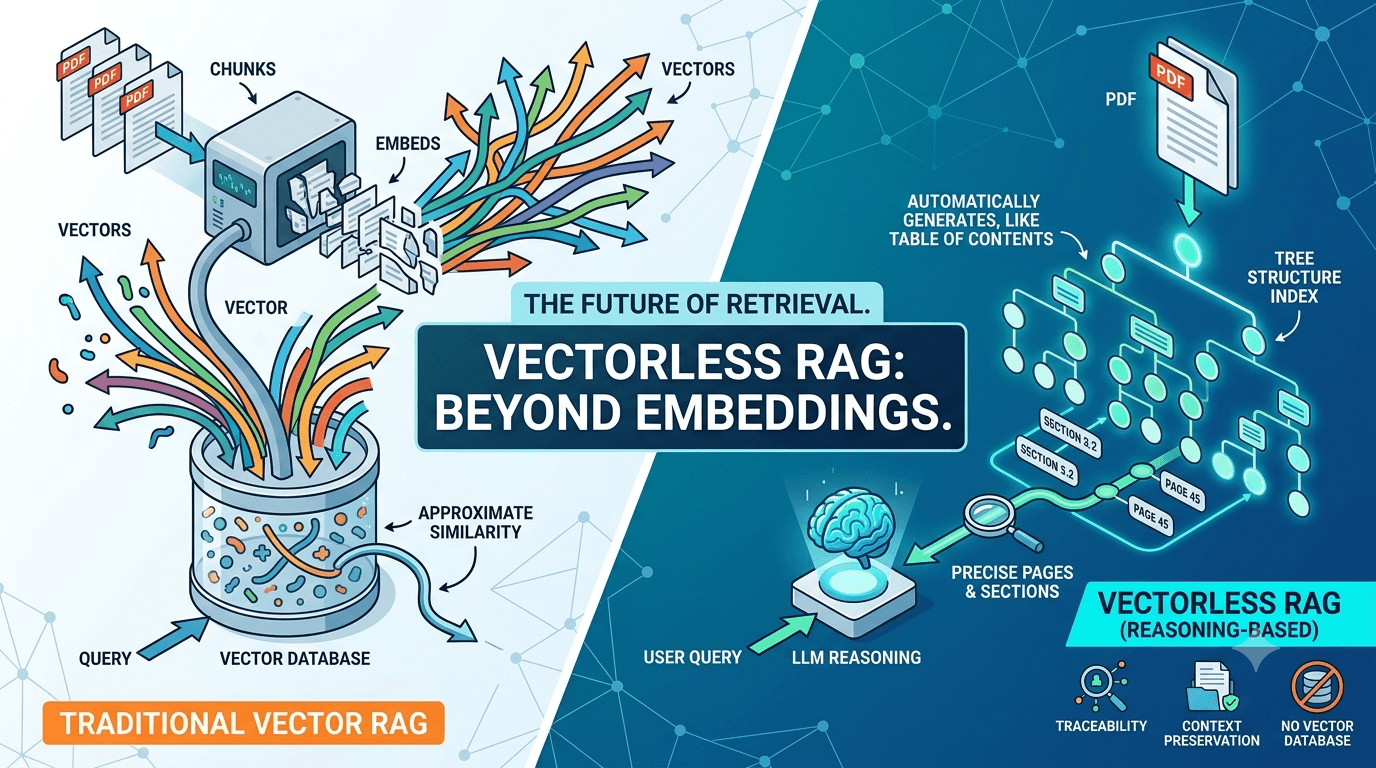
You want to build an AI assistant that answers questions from your company's documents.
The usual advice sounds almost automatic:
- Split every document into chunks
- Convert the chunks into embeddings
- Store them in a vector database
- Embed the user's question
- Retrieve the nearest chunks
- Send them to an LLM
That architecture is useful, but it is not the only way to build Retrieval-Augmented Generation.
Sometimes your data already lives in PostgreSQL. Sometimes users search for exact product codes, contract clauses, error messages, dates, or employee IDs. Sometimes documents have a strong table of contents that is more useful than mathematical similarity. And sometimes adding an embedding model, vector index, synchronization pipeline, and another database creates more complexity than value.
This is where vectorless RAG becomes interesting.
What is RAG?
Retrieval-Augmented Generation, or RAG, is a technique that gives a language model relevant external information before asking it to generate an answer.
Without RAG:
User question
↓
LLM
↓
Answer from the model's existing knowledgeWith RAG:
User question
↓
Search an external knowledge source
↓
Retrieve relevant evidence
↓
Send question + evidence to the LLM
↓
Grounded answerThe goal is not simply to make an LLM sound more knowledgeable. The goal is to ground its answer in information that is private, current, domain-specific, or otherwise unavailable in its original training.
RAG has three essential parts:
- Retrieval: find useful information
- Augmentation: place that information into the model's context
- Generation: produce an answer based on the supplied evidence
Notice what is missing from that definition: RAG does not require vectors.
What is vector-based RAG?
In a common RAG pipeline, documents are divided into chunks and passed through an embedding model.
The embedding model converts each chunk into a list of numbers called a vector:
"Employees receive 20 days of annual leave."
↓ embedding model
[0.018, -0.247, 0.731, ..., 0.092]The user's question is converted into a vector in the same way:
"How many vacation days do employees get?"
↓ embedding model
[0.021, -0.229, 0.714, ..., 0.105]A vector search engine compares these vectors and returns chunks that are mathematically close to the query.
This is called dense retrieval or semantic search because it can find conceptually similar text even when the wording is different.
For example:
Query: "How much holiday time do workers receive?"
Document: "Employees receive 20 days of annual leave."The query and document share few exact words, but their meanings are similar. Vector search is designed to recognize that relationship.
So what is vectorless RAG?
Vectorless RAG is a RAG architecture that retrieves context without relying on dense embeddings or a vector database.
It may retrieve information using:
- keyword or full-text search
- BM25 ranking
- SQL queries and filters
- metadata lookup
- document headings and tree structures
- knowledge graph traversal
- regular expressions or exact matching
- an LLM agent that performs multiple searches
- a combination of these methods
A simple vectorless pipeline can look like this:
User question
↓
Extract keywords, entities, and filters
↓
Search with PostgreSQL, Elasticsearch, or another text index
↓
Rank and optionally rerank the results
↓
Send the best passages to the LLM
↓
Generate an answer with citationsThe system still retrieves external evidence and augments the prompt. Only the retrieval mechanism has changed.
Vectorless RAG means no dense-vector retrieval. It does not mean no index, no database, no ranking, or no search.
Vectorless RAG is not one algorithm
The term can be confusing because different teams use it for different architectures.
One system may call PostgreSQL full-text search vectorless RAG. Another may let an LLM navigate a document's table of contents. A third may query a knowledge graph. All three avoid dense embedding search, but they operate differently.
It is more accurate to treat vectorless RAG as an architecture category, not a specific product or algorithm.
Let us examine its main forms.
Approach 1: Keyword and full-text retrieval
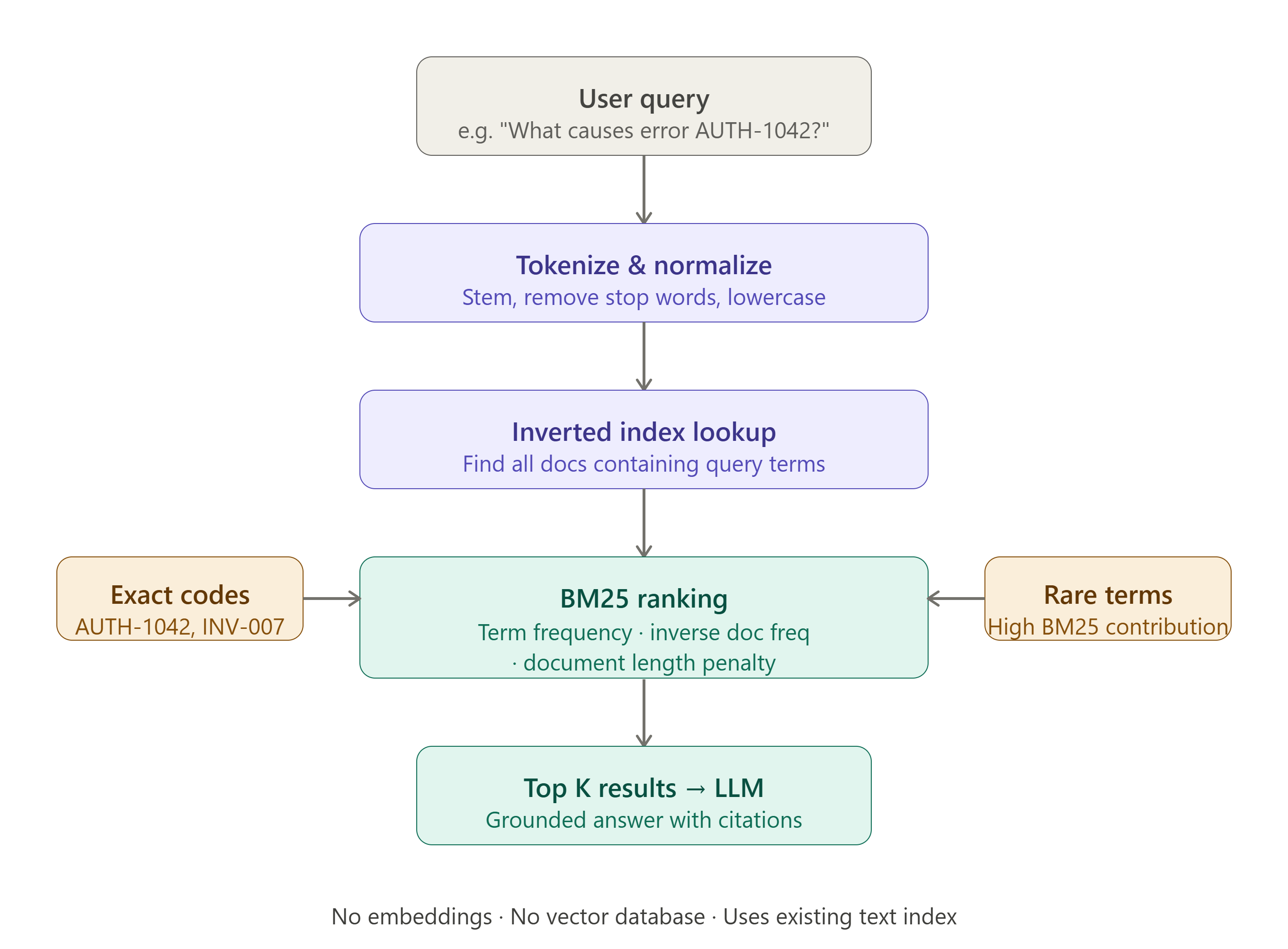
The most direct approach uses lexical search. It retrieves documents based on the words that appear in both the query and the indexed content.
This is more capable than writing:
WHERE content LIKE '%annual leave%'A proper full-text search engine typically:
- tokenizes text into searchable terms
- normalizes words
- removes or reduces the effect of common words
- builds an inverted index
- ranks matching documents by relevance
Search engines often use BM25, a ranking method that considers:
- how often a query term appears in a document
- how rare that term is across all documents
- the length of the document
Rare, meaningful terms generally contribute more than words that appear everywhere.
Why exact terms matter
Imagine a user asks:
What causes error AUTH-1042?The exact identifier AUTH-1042 is highly important. Lexical search can find it directly. A semantic embedding may understand that the query is about authentication errors, but it can sometimes rank a generally related passage above the one containing the exact code.
Keyword retrieval works particularly well for:
- product codes
- legal clause numbers
- invoice IDs
- function and class names
- error messages
- technical terminology
- names and abbreviations
Approach 2: SQL and metadata retrieval
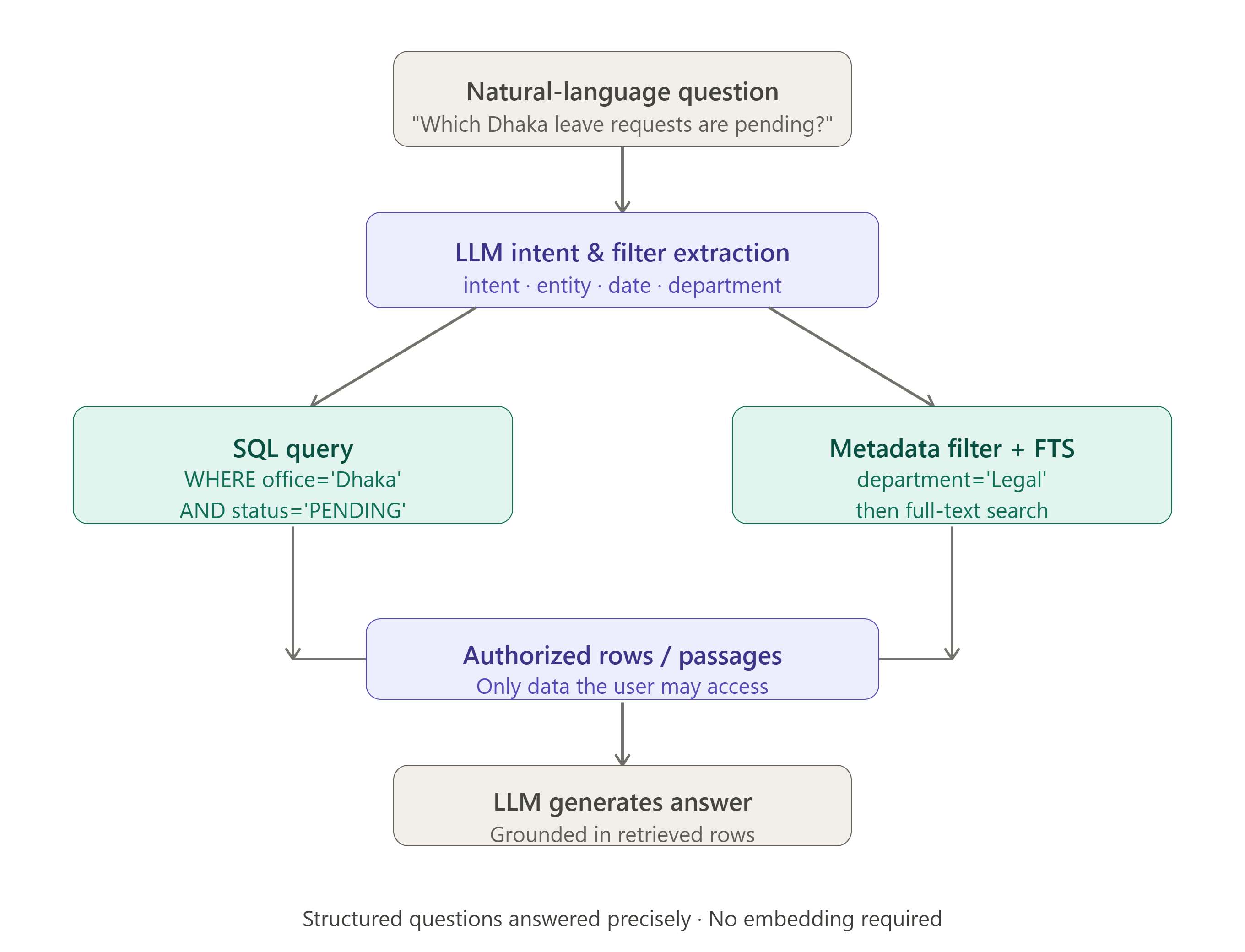
Not every question should search unstructured text.
Suppose an employee asks:
Which leave requests from the Dhaka office are still pending?The answer may already exist as structured rows:
SELECT employee_name, leave_type, start_date, end_date
FROM leave_requests
WHERE office = 'Dhaka'
AND status = 'PENDING';Turning those rows into embeddings would add uncertainty to a problem that SQL can answer precisely.
An LLM can identify the intent and parameters, while your application constructs or selects a safe query:
Intent: list_leave_requests
Filters:
office = Dhaka
status = PENDINGThe backend retrieves the authorized rows and gives them to the model as context.
This is still RAG. The external knowledge came from a relational database instead of a vector store.
Metadata can narrow the search space
Even when the main content is text, metadata can make retrieval much more precise:
- document type
- department
- author
- publication date
- customer ID
- access level
- language
- country
- version
For example:
SELECT id, title, content
FROM documents
WHERE department = 'Legal'
AND document_type = 'Lease'
AND created_at >= DATE '2026-01-01';The system can then run full-text search only over that smaller, relevant set.
Approach 3: Structure-aware document retrieval
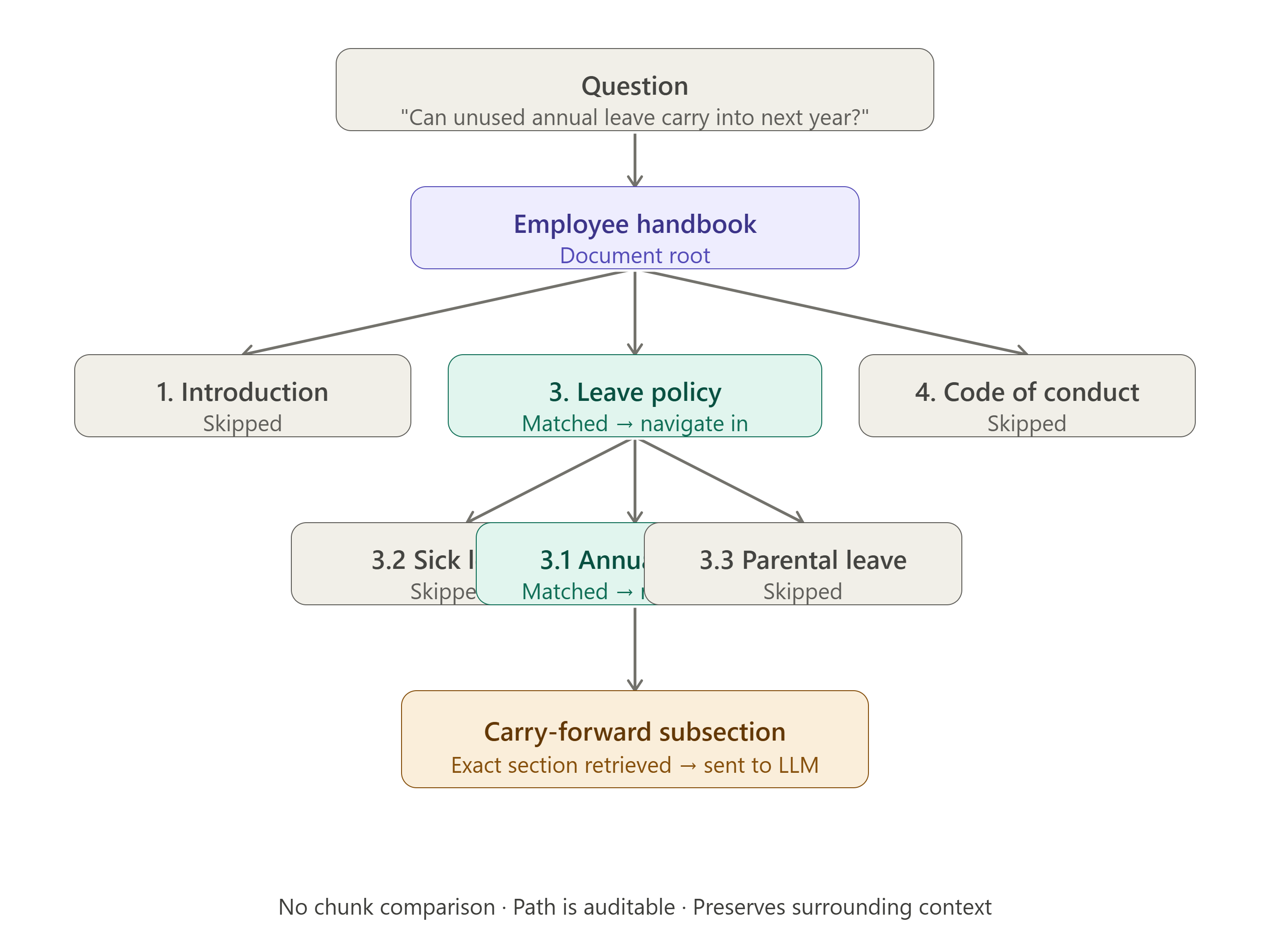
Large documents are not random collections of paragraphs. They have structure:
- titles
- chapters
- headings
- subheadings
- tables
- appendices
- page numbers
A structure-aware system creates a hierarchical representation:
Employee Handbook
├── 1. Introduction
├── 2. Employment Policies
│ ├── 2.1 Working Hours
│ └── 2.2 Remote Work
├── 3. Leave Policy
│ ├── 3.1 Annual Leave
│ ├── 3.2 Sick Leave
│ └── 3.3 Parental Leave
└── 4. Code of ConductFor the question:
Can unused annual leave be carried into next year?An LLM or deterministic search process can navigate:
Employee Handbook
→ Leave Policy
→ Annual Leave
→ Carry-forward subsectionThe system retrieves the relevant section or pages without comparing embedding vectors.
This approach can preserve more context than fixed-size chunking. It also makes the retrieval path easier to explain: the system selected a chapter because its heading and summary matched the question.
Approach 4: Knowledge graph retrieval
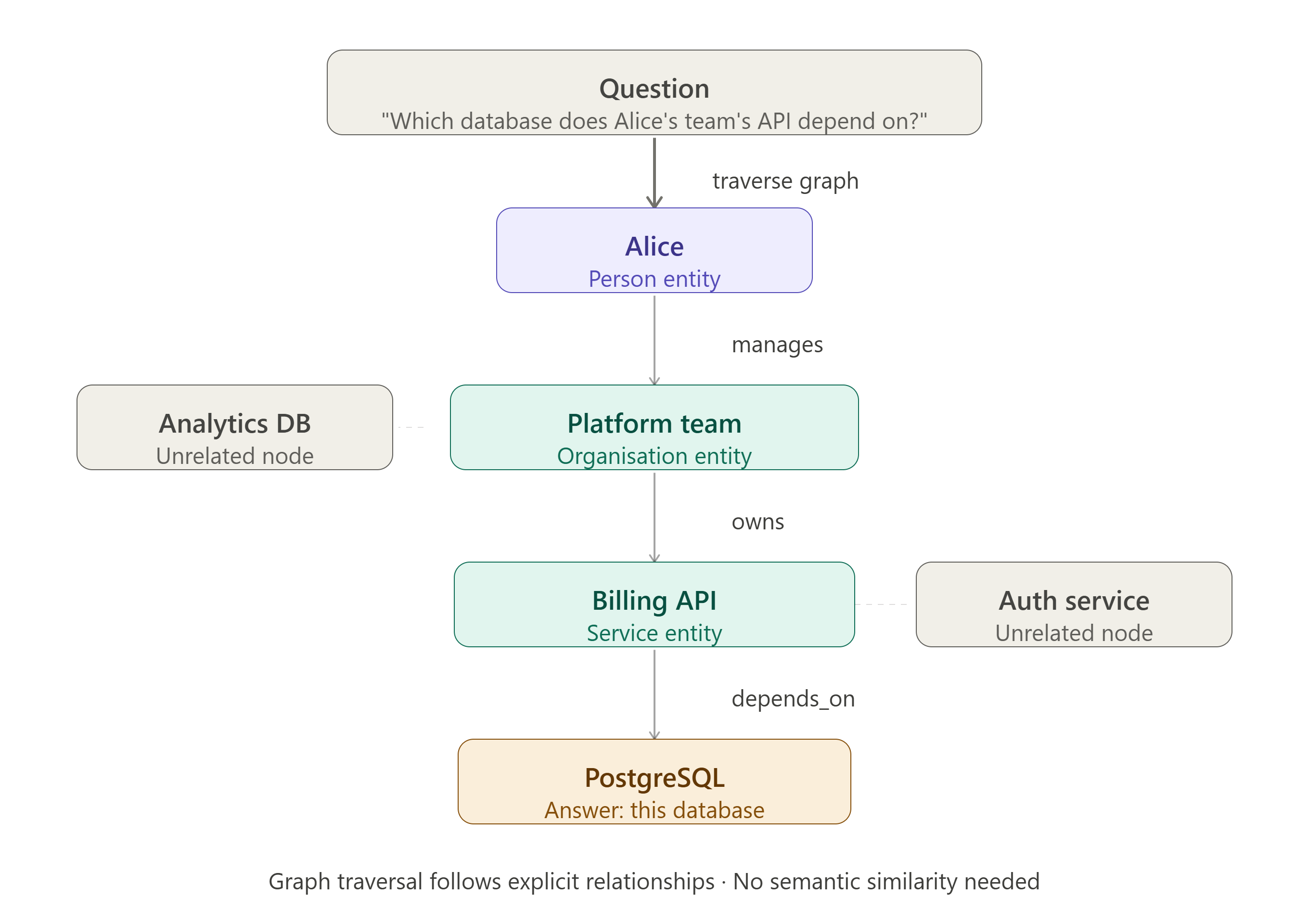
Some information is best represented as entities and relationships.
Consider:
Alice manages the Platform team.
The Platform team owns the Billing API.
The Billing API depends on PostgreSQL.A knowledge graph could represent this as:
Alice ──manages──> Platform Team
Platform Team ──owns──> Billing API
Billing API ──depends_on──> PostgreSQLTo answer:
Which database is used by the API owned by Alice's team?The retriever follows relationships across the graph. A simple similarity search may retrieve individually related passages, but graph traversal explicitly preserves how the facts connect.
Graph-based retrieval is useful when questions involve:
- multiple relationships
- organizational hierarchies
- dependencies
- ownership
- supply chains
- fraud networks
- connected events
The graph itself does not need dense vectors, although some systems combine graph traversal with vector search.
Approach 5: Agentic search
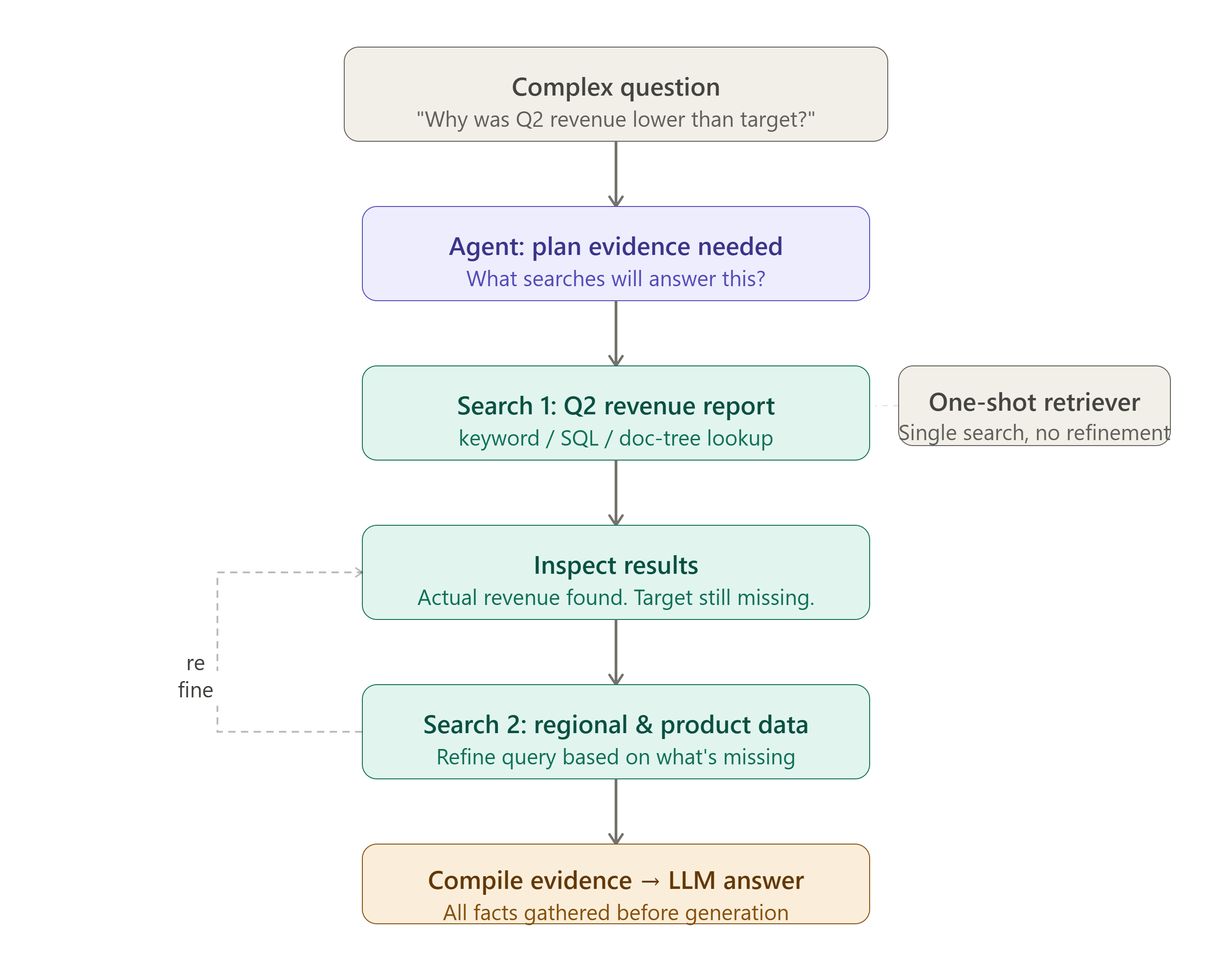
A one-shot retriever performs one search and returns the top results. An agentic retriever can search repeatedly.
For example, a user asks:
Why was the Q2 revenue lower than the target?An agent might:
- Search for the Q2 revenue report
- Extract the actual revenue and target
- Search for regional performance
- Search for product-level declines
- inspect management commentary
- combine the evidence
Its process may look like this:
Question
↓
Plan what evidence is needed
↓
Run keyword, SQL, or document-tree searches
↓
Inspect the results
↓
Refine the query if evidence is missing
↓
Generate the final answerThis resembles how a person researches a question. Instead of trusting one nearest-neighbor search, the model can decide what to search next based on what it has already found.
The trade-off is that multiple LLM calls can increase latency and cost.
A practical example with PostgreSQL
Suppose we have a table of internal documents:
CREATE TABLE documents (
id BIGSERIAL PRIMARY KEY,
title TEXT NOT NULL,
department TEXT NOT NULL,
content TEXT NOT NULL,
search_vector TSVECTOR
);We can populate a PostgreSQL full-text search vector:
UPDATE documents
SET search_vector =
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(content, '')), 'B');The title receives a higher weight because a match there may be more meaningful than a match deep inside the body.
Next, create a GIN index:
CREATE INDEX documents_search_idx
ON documents
USING GIN (search_vector);Now we can retrieve and rank relevant documents:
WITH query AS (
SELECT websearch_to_tsquery(
'english',
'annual leave carry forward'
) AS value
)
SELECT
id,
title,
content,
ts_rank_cd(search_vector, query.value) AS score
FROM documents, query
WHERE search_vector @@ query.value
AND department = 'HR'
ORDER BY score DESC
LIMIT 5;The application sends those results to an LLM:
const context = results
.map((doc, index) => (
`[Source ${index + 1}: ${doc.title}]\n${doc.content}`
))
.join("\n\n");
const prompt = `
Answer the question using only the provided sources.
If the sources do not contain the answer, say that you do not know.
Cite the source number used for each important claim.
Question:
${question}
Sources:
${context}
`;That is a complete basic RAG pipeline:
Question
↓
PostgreSQL full-text retrieval
↓
Top matching documents
↓
Prompt augmentation
↓
LLM answerThere is no embedding model and no vector database.
Improving the basic pipeline
A production system needs more than one search query. Several improvements can make vectorless retrieval much stronger.
1. Query rewriting
Users do not always use the same vocabulary as the documents.
The model can rewrite:
Can I move unused vacation to next year?Into search terms such as:
annual leave carry forward unused days next yearThis keeps lexical retrieval while reducing vocabulary mismatch.
2. Synonyms and domain dictionaries
Your search layer can understand that:
vacation = annual leave
employee = staff member
PO = purchase order
SLA = service-level agreementDomain-specific synonyms are often more reliable than assuming a general embedding model understands every internal abbreviation.
3. Multiple searches
Run several queries with different wording, then merge the results:
"annual leave carry forward"
"unused vacation next year"
"leave balance rollover"This increases recall while still using lexical retrieval.
4. Reranking
The search engine can retrieve 20 candidates cheaply. A stronger model can then inspect those candidates and select the best 5.
Keyword search: retrieve broadly
↓
Reranker: judge query-document relevance
↓
LLM: answer from the strongest evidenceThe reranker does not have to be a vector database. It can be a cross-encoder, an LLM, or deterministic business logic.
5. Parent-section expansion
A matching paragraph may not contain enough context. After locating it, retrieve:
- its heading
- the complete section
- nearby paragraphs
- relevant table rows
- the document title and version
This avoids giving the LLM a sentence that is relevant but incomplete.
6. Access control before generation
Retrieval must respect authorization.
WHERE organization_id = $1
AND department = ANY($2)
AND access_level <= $3Do not retrieve restricted content and then ask the LLM to hide it. Unauthorized data should never enter the model's context.
Why teams choose vectorless RAG
Simpler infrastructure
If your organization already uses PostgreSQL, Elasticsearch, OpenSearch, or another search engine, you may not need a separate vector database.
That means fewer components to:
- deploy
- monitor
- secure
- synchronize
- back up
- pay for
No embedding pipeline
Vector RAG requires embeddings to be generated and updated.
When a document changes, the system may need to:
- detect the update
- split the document again
- generate new embeddings
- remove outdated vectors
- insert the replacements
Vectorless retrieval can often index changed text directly using an existing search or database pipeline.
Strong exact-match performance
Lexical systems naturally handle values whose exact spelling matters:
INV-2026-00491NullPointerExceptionsection 14.2(b)getUserByIdBES-LEASE-107
These are common in enterprise, legal, and technical applications.
Easier debugging
Keyword and SQL retrieval are often easier to inspect.
You can ask:
- Which terms matched?
- Which filter excluded the document?
- Why did this document receive its score?
- Which SQL query was executed?
- Which document path did the agent follow?
Vector similarity scores are useful, but they can be harder to explain to developers and users.
Better use of structured data
SQL is excellent at:
- filtering
- joining
- counting
- grouping
- sorting
- aggregating
An embedding search should not replace precise database operations when the question is fundamentally structured.
Where vectorless RAG struggles
Vectorless RAG is not automatically better.
Vocabulary mismatch
If the user says car while the document only says automobile, a basic keyword search may miss it.
Stemming, synonyms, query expansion, and LLM rewriting help, but dense retrieval handles many semantic variations naturally.
Vague or conceptual questions
Consider:
Which policies could negatively affect employee well-being?The relevant sections may never contain the words negatively affect or well-being. Semantic retrieval may identify conceptually related content more easily.
Search agents can be slower
An agent that plans, searches, reads, and searches again may require several model calls. A vector query can often retrieve candidates in one operation.
LLM-based selection costs tokens
If the system asks a model to inspect every page or every section, the cost can grow quickly. Good indexing and progressive narrowing are still necessary.
Hierarchical retrieval depends on document quality
Document-tree navigation works best when headings and sections are meaningful. Poorly scanned PDFs, inconsistent formatting, and missing structure reduce its effectiveness.
Vectorless RAG vs vector RAG
| Area | Vectorless RAG | Vector RAG | |---|---|---| | Retrieval signal | Words, fields, structure, relationships, reasoning | Embedding similarity | | Extra embedding model | Not required | Required | | Vector database | Not required | Usually required | | Exact identifiers | Usually strong | Can be inconsistent | | Semantic similarity | Requires rewriting, synonyms, or reasoning | Naturally strong | | Structured filters | Excellent with SQL and metadata | Usually combined with metadata filters | | Explainability | Often easier to inspect | Similarity can be less intuitive | | Document updates | Often straightforward | May require re-embedding | | Operational complexity | Can reuse existing systems | Adds embedding and vector-index workflows | | Best fit | Exact, structured, or well-organized knowledge | Paraphrased and concept-heavy questions |
Neither architecture wins every time.
What about hybrid RAG?
You do not have to choose one method for every query.
A hybrid RAG system combines retrieval signals:
User question
↓
┌────┴─────────────┐
↓ ↓
BM25 search Vector search
↓ ↓
└────┬─────────────┘
↓
Merge and rerank
↓
LLM answerAnother hybrid system might route by query type:
Exact ID or error code → keyword search
Analytics question → SQL
Relationship question → knowledge graph
Conceptual question → vector search
Long document question → document-tree navigationThis is often the most practical production design. The goal is not to defend one retrieval technology. The goal is to return the best evidence for the user's question.
When should you use vectorless RAG?
Vectorless RAG is a strong choice when:
- your data already lives in a searchable relational database
- questions depend on exact terms, IDs, clauses, or error codes
- your documents have reliable headings and hierarchy
- metadata filters are essential
- content changes frequently
- you need a simple first version
- infrastructure cost and maintenance matter
- retrieval decisions must be easy to audit
- data is mostly structured or semi-structured
Vector retrieval is likely valuable when:
- users frequently paraphrase the source material
- questions are vague or conceptual
- the same idea appears under many different expressions
- documents have little useful structure
- semantic similarity is more important than exact wording
Use hybrid retrieval when both kinds of questions are common.
How to evaluate the decision
Do not choose an architecture from a diagram alone. Build a test set from real questions.
For each question, record:
- the expected answer
- the document or rows containing the evidence
- required access restrictions
- whether exact words appear in the source
Then measure:
- Recall@K: did the correct evidence appear in the top K results?
- Precision@K: how much of the retrieved context was actually useful?
- Answer correctness: did the final answer match the expected answer?
- Faithfulness: was the answer supported by the retrieved evidence?
- Latency: how long did retrieval and generation take?
- Cost: what did indexing, storage, search, reranking, and generation cost?
Compare at least:
- Full-text or BM25 retrieval
- Vector retrieval
- Hybrid retrieval
- Optional SQL, graph, or structure-aware routing
A fashionable architecture that fails your real questions is still the wrong architecture.
A sensible implementation plan
For many teams, the following progression is practical:
Phase 1: Start with existing search
Use full-text search, metadata filters, and SQL. Add citations and log every retrieved source.
Phase 2: Build an evaluation set
Collect real user questions and identify where retrieval succeeds or fails.
Phase 3: Improve lexical recall
Add query rewriting, synonyms, multiple searches, and parent-section expansion.
Phase 4: Add reranking
Retrieve a broad candidate set and use a stronger relevance model to remove noise.
Phase 5: Add vectors only where they help
If evaluation shows that conceptual or paraphrased questions still fail, add semantic retrieval for those cases.
This keeps the system evidence-driven. You introduce complexity because a measured problem requires it, not because every RAG diagram contains a vector database.
Common misconceptions
“Vectorless RAG is just Ctrl+F”
It can use exact matching, but a real system may include BM25 ranking, language analysis, metadata filtering, query rewriting, reranking, graph traversal, and iterative agent search.
“Without embeddings, the LLM cannot understand the query”
The LLM can still classify intent, extract entities, rewrite queries, choose tools, inspect results, and generate the final answer. Embeddings are one retrieval technique, not the model's only source of understanding.
“Vector databases are unnecessary”
That conclusion is too broad. Vector search is extremely useful when meaning matters more than wording. Vectorless RAG simply shows that it should not be treated as mandatory.
“Using PostgreSQL makes the system small-scale”
Scale depends on data volume, indexing, query patterns, hardware, and operational design. PostgreSQL full-text search can be enough for many applications, while dedicated search infrastructure may be appropriate for larger or more specialized workloads.
“No vectors means no chunking”
Some vectorless systems avoid fixed chunks by navigating pages or sections. Others still divide documents into paragraphs or passages for indexing and prompt construction. Vectorless and chunkless are separate decisions.
What to remember
RAG is not defined by embeddings. It is defined by retrieving external evidence and giving that evidence to a generative model.
Vectorless RAG performs that retrieval with tools such as:
- full-text and BM25 search
- SQL and metadata filters
- document hierarchy
- knowledge graphs
- exact matching
- LLM-guided, multi-step search
Its biggest strengths are simplicity, exact retrieval, structured-data support, fast updates, and easier debugging. Its biggest weakness is semantic mismatch when users and documents express the same idea with different words.
The right question is not:
Should we use a vector database?The better question is:
What retrieval method finds the best evidence for our real users,
with acceptable accuracy, latency, cost, and complexity?Sometimes the answer is vector search. Sometimes it is SQL or BM25. Often it is a combination.
Good RAG is not about collecting the most fashionable components. It is about retrieving the right evidence before the model starts talking.
Tagged
Comments
Join the discussion. Your email is never shown publicly.